
Neural Networks Without Magic: Occam’s Razor from a Programmer’s Desk
AI doesn’t have to feel mystical. High-school math, a few derivatives, and clean C++/MQL5 code are enough. No spells—just matrices, functions, and discipline. This is how I build it in practice.
What you actually need
Neural-network articles often add fog. I use Occam’s razor and keep the essentials—the stuff most of us remember from school:
- multiplication and addition,
- simple nonlinearities (tanh, sigmoid, ReLU),
- basic vector and matrix work,
- and derivatives for learning (backpropagation).
That’s it. Everything else is convenience, not necessity.
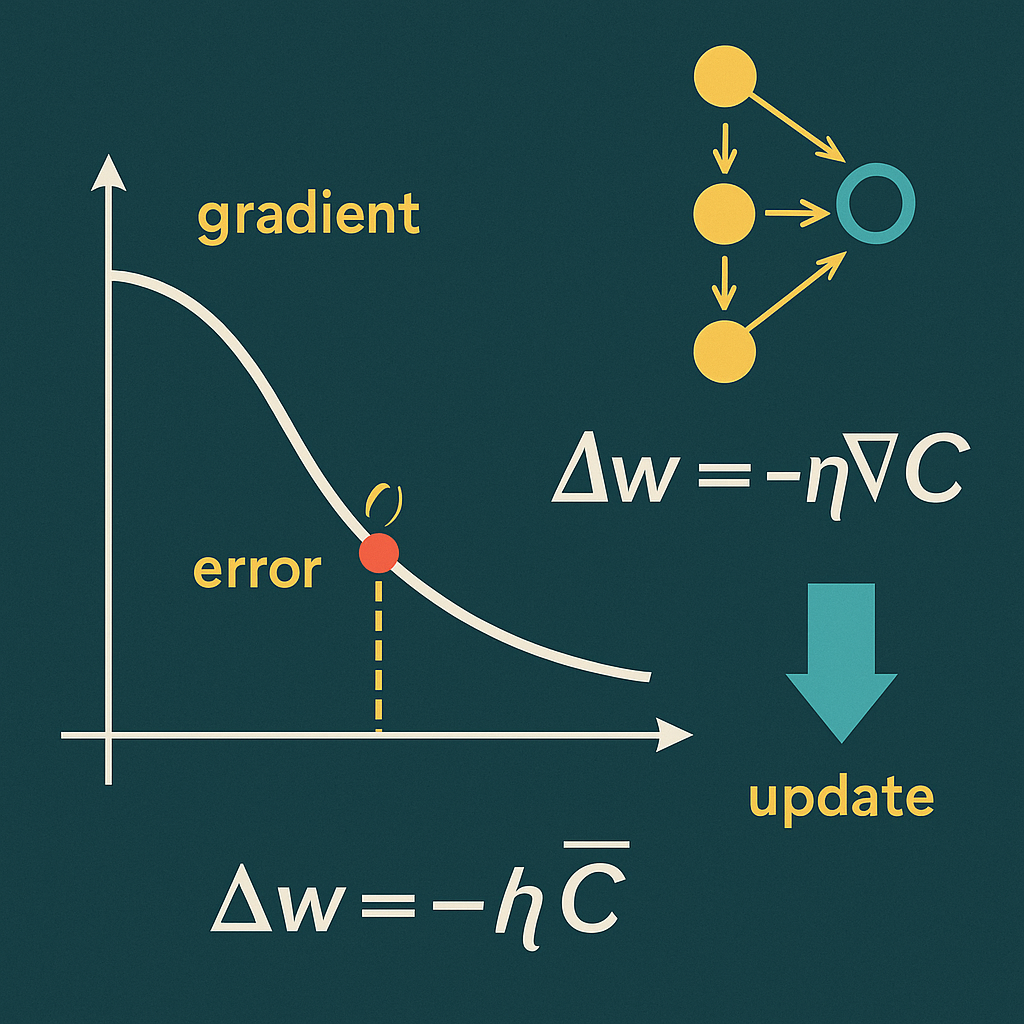
Derivatives: the only “mandatory optional”
Without derivatives you get a forward pass and a number. Learning needs a direction. The chain rule turns error into updates: compute the loss, send it back through the layers, adjust weights and biases using derivatives of the activations and the linear parts.
- Error: prediction vs. reality (MSE).
- Gradient: derivative of a composite function (chain rule).
- Update: a small step that reduces the error (SGD).
If you can differentiate sigmoid, tanh and the ReLU “derivative”, you’ve covered 99% of day-to-day work.
C++ and MQL5: from math to a running chart
In C++ I use a small DLL: dense layers, activations, forward/backprop, single-sample and mini-batch training. A plain C API (handle-based, no global singletons). In MQL5, the EA takes data straight from the chart, normalizes it, feeds the network, and draws the outputs.
y = f(Wx + b)— forward pass.dL/dW,dL/db— gradients via activation derivatives.- SGD, MSE, gradient clipping, He/Xavier init.
- Batch wrappers for throughput (
NN_ForwardBatch,NN_TrainBatch). - Weights access for tools (
NN_GetWeights,NN_SetWeights).
The effect is simple: AI stops looking magical and turns back into engineering.
Occam, condensed
- Forward: matrix × vector.
- Activation: tanh/sigmoid/ReLU are ordinary functions.
- Loss (MSE): mean of squared differences.
- Backprop: just the chain rule.
Complexity comes from stacking simple parts, not from mystery.
What this approach gives me
I treat a network as a calculator, not an oracle. I know its limits and its strengths. And I own the toolchain: save/load weights in the host app, add Adam later, extend outputs, plug it into trading logic when needed.
High-school math, patience, and the habit of shaving off ballast go a long way.
Conclusion
Neural networks aren’t a black box. They’re numbers in matrices and a handful of derivatives—a mechanical recipe I write in the languages I enjoy: C++ and MQL5.
Download (EA / sources)
NNMQL5 — documentation:
A lightweight DLL with a C API for a simple MLP (a stack of dense layers):
- forward inference (
NN_Forward,NN_ForwardBatch) - training: per-sample and mini-batch (
NN_TrainOne,NN_TrainBatch) - multiple networks managed by integer handles
- weights read/write for tooling/debug (
NN_GetWeights,NN_SetWeights)
The network is stateful (weights in RAM); persistence stays in the host (e.g., via NN_Get/SetWeights in MQL).
Features
- Dense layers:
W[out × in], biasb[out] - Activations:
SIGMOID,RELU,TANH,LINEAR,SYM_SIG - Init: He for ReLU, Xavier-like for others
- Gradient clipping (per neuron, ±5)
- Double precision, x64 build (MSVC)
- C ABI (no name mangling) → simple from MQL5
- Batch wrappers for throughput
- Weights I/O for reproducible runs
Deliberate limitations
- Only vanilla SGD (no Adam/Nesterov yet)
- No built-in serialization (persist in the host)
- Thread safety: calls for one handle must be serialized by the host
Binary / Build info
- Platform: Windows x64, MSVC (Visual Studio)
- Exports:
extern "C" __declspec(dllexport) - Exceptions: never cross the C boundary; API returns
bool/int - Threading: instance table guarded by
std::mutex; per-network ops are not re-entrant
Suggested VS settings
- Configuration:
Release | x64 - C++:
/std:c++17(or newer),/O2,/EHsc - Runtime:
/MD(shared CRT)
API (C interface)
All functions use the C ABI. Signatures:
// Create / free
int NN_Create(void);
void NN_Free(int h);
// Topology (act: 0=SIGMOID, 1=RELU, 2=TANH, 3=LINEAR, 4=SYM_SIG)
bool NN_AddDense(int h, int inSz, int outSz, int act);
// Introspection
int NN_InputSize(int h);
int NN_OutputSize(int h);
// Inference
bool NN_Forward(int h, const double* in, int in_len,
double* out, int out_len);
bool NN_ForwardBatch(int h, const double* in, int batch, int in_len,
double* out, int out_len);
// Training (SGD + MSE)
bool NN_TrainOne(int h, const double* in, int in_len,
const double* tgt, int tgt_len,
double lr, double* mse);
bool NN_TrainBatch(int h, const double* in, int batch, int in_len,
const double* tgt, int tgt_len,
double lr, double* mean_mse);
// Weights access
bool NN_GetWeights(int h, int i, double* W, int Wlen, double* b, int blen);
bool NN_SetWeights(int h, int i, const double* W, int Wlen, const double* b, int blen);
Activation codes (act)
| Code | Activation | Notes |
|---|---|---|
| 0 | SIGMOID | 1/(1+e^{-x}) |
| 1 | RELU | max(0,x), He init |
| 2 | TANH | \tanh(x) |
| 3 | LINEAR | Identity |
| 4 | SYM_SIG | 2·sigmoid(x)-1 ∈ (-1,1) |
Lifecycle (recommended)
h = NN_Create()- Topology via
NN_AddDense(...)in order- First layer sets the input size
- Last layer sets the output size
- Sizes must match:
out(k-1) == in(k)→ otherwisefalse
- Optionally check
NN_InputSize(h),NN_OutputSize(h) - Training: loop
NN_TrainOneorNN_TrainBatch - Inference:
NN_ForwardorNN_ForwardBatch NN_Free(h)
Semantics
- Validation: functions return
falsefor invalid handle, empty network, or size mismatch. - Memory safety: caller allocates and owns buffers; the DLL only reads/writes.
- Numerics: double I/O; gradient clipping ±5 per neuron; He/Xavier-like init.
- Instances: any number of independent networks (separate handles).
- Re-entrancy: don’t call into the same handle concurrently.
Performance notes
- Allocate in
OnInit; train via timer; avoid per-tick create/destroy - Reuse MQL arrays to cut allocations
- Balance lookback window vs. network width/depth
MQL5 compatibility
doubleABI matches (8 bytes)- Arrays passed by reference; the DLL reads/writes via raw pointers
boolmapping is standard (0/1)
Troubleshooting
NN_AddDensereturns false: size mismatch (e.g., 8→16 then 32→1). Fix to 8→16→1 or adjust layer sizes.NN_Forward/Train*false: wrong lengths or invalid handle / empty network.- No learning: tune
lr, normalize data, use LINEAR output for unbounded regression.
NNMQL5_Predictor — Examples (Dark)
Code snippets based on indicator NNMQL5_Predictor.mq5 (MetaTrader 5 • NNMQL5.dll).
License
“MIT-like spirit”: use freely, please keep attribution.

Author: Tomáš Bělák — Remind