
Neuronové sítě bez magie: Okamova břitva a programátorský pohled
Umělá inteligence nemusí být esoterika. Stačí středoškolská matematika, pár derivací a čistý kód v C++/MQL5. Žádná kouzla — jen čísla v maticích, funkce a disciplína.
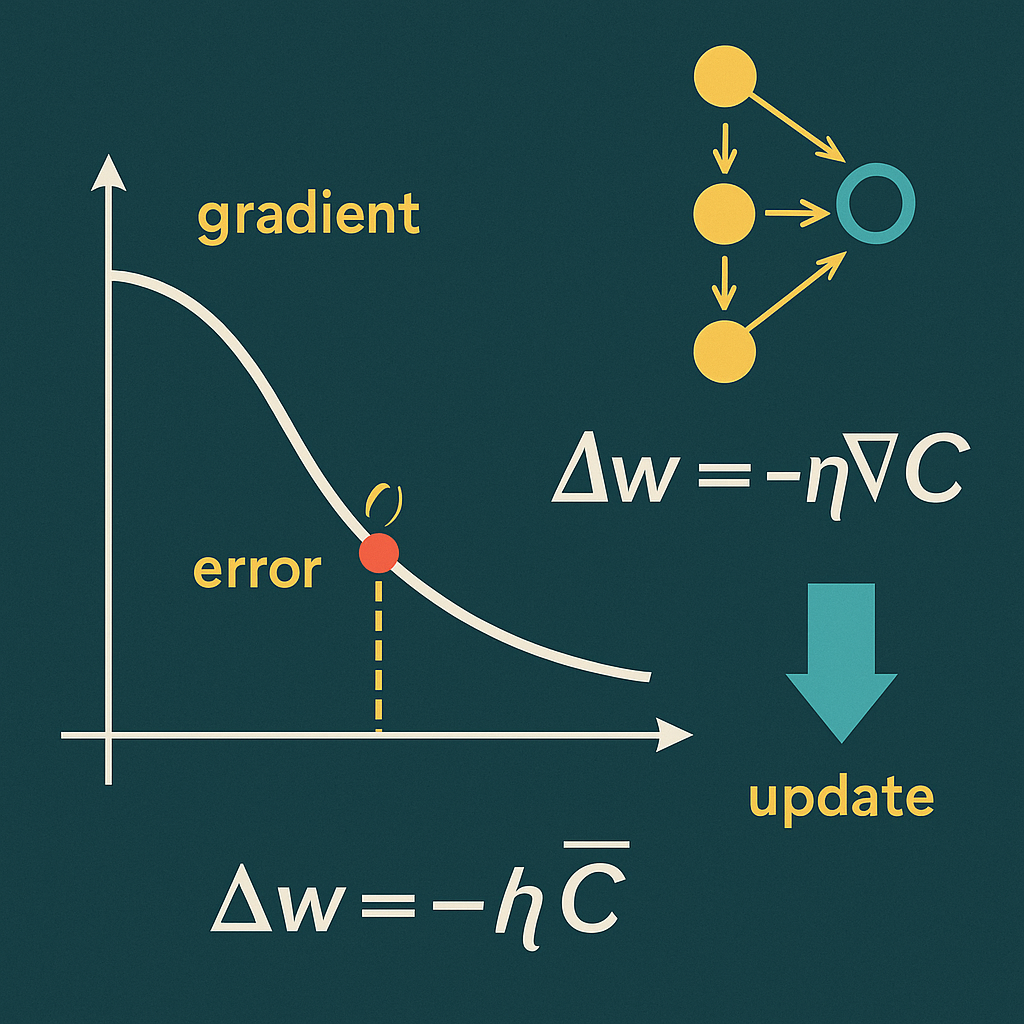
Problém bez mlhy: co opravdu potřebujeme
V textech o neuronových sítích bývá mnoho „kouře a zrcadel“. Já jsem použil okamovu břitvu a nechal jen to, co je nezbytné — matematické minimum, které si každý pamatuje ze střední školy:
- násobení a sčítání čísel,
- jednoduché nelineární funkce (tanh, sigmoid, ReLU),
- základní práce s vektory a maticemi,
- a derivace pro učení (zpětné šíření chyby).
To je celé. Všechno ostatní je jen komfort, nikoli nutnost.
Derivace: jediná „nepovinná povinná“ kapitola
Bez derivací získáme jen výsledek dopředného průchodu. Ale učení vyžaduje vědět, jak upravit každou váhu. Tady nastupuje řetězové pravidlo: spočtu chybu, pošlu ji zpět vrstvami a podle derivací aktivací a lineárních částí upravím váhy i biasy.
- Chyba: rozdíl predikce a skutečnosti (MSE).
- Gradient: derivace složené funkce (řetězové pravidlo).
- Update: malý krok po směru snižování chyby (SGD).
Pokud zvládneš derivaci sigmoidy, tanh a „derivaci ReLU“, máš 99 % potřeby pokryto.
C++ a MQL5: matematika přepsaná do praxe
V C++ mám lehkou DLL: husté vrstvy (Dense), aktivace, dopředný průchod, backprop a učení po jednom vzorku (SGD). Vše přes jednoduché C API (handle, žádné globální singletony). V MQL5 pak bere EA data přímo z grafu, normalizuje je, krmí síť a kreslí výstupy.
y = f(Wx + b)— dopředný průchod.dL/dW,dL/db— gradienty přes derivace aktivací.- SGD, MSE, gradient clipping, He/Xavier init.
Výsledek: AI se přestává tvářit magicky. Zůstává programátorské řemeslo se srozumitelným chováním.

Okamova břitva v bodech
- Forward pass: násobení matice a vektoru.
- Aktivace: tanh/sigmoid/ReLU jako obyčejné funkce.
- Loss (MSE): průměr čtverců rozdílů.
- Backpropagation: čisté řetězové pravidlo.
Komplexita vzniká vrstvením jednoduchých věcí, ne tajemstvím.
Co mi tahle cesta dala
Vidím síť jako systém počítání, nikoli věštbu. Vnímám limity i možnosti. A mám nástroj, který mohu rozšiřovat: uložit/načítat váhy, přidat Adam, více výstupů, propojit s obchodní logikou.
Stačí SŠ matematika, trpělivost a chuť odstranit balast.
Závěr
Neuronové sítě nejsou černá skříňka. Jsou to čísla v maticích a pár derivací — matematický mechanismus převedený do jazyků, které mám rád: C++ a MQL5.
Ke stažení (EA / zdroje)
Dokumentace DLL pro vaše osobní použití
Lehká DLL poskytující C API pro jednoduchý MLP (sekvence hustých vrstev) s:
- dopředným průchodem (
NN_Forward), - online tréninkem po jednom vzorku (
NN_TrainOne, SGD), - správou více instancí sítí přes celočíselné handle.
Síť je stavová (váhy v RAM), bez perzistence.
Vlastnosti
- Dense vrstvy (matice
W[out x in], biasb[out]). - Aktivace:
SIGMOID,RELU,TANH,LINEAR,SYM_SIG(symetrická sigmoida). - Inicializace vah: He pro ReLU, jinak Xavier-like.
- Základní gradient clipping (per-neuron, ±5) ve zpětném průchodu.
- Double přesnost, 64bit build (MSVC, x64).
- C ABI (žádné jmenné dekorace), snadno volatelné z MQL5.
Omezení / Co DLL úmyslně neumí
- Jen SGD po jednom vzorku (žádné batch-e, žádný Adam apod.).
- Bez ukládání/načítání modelu (serialize/deserialize).
- Bez řízení RNG seedů (viz „Reprodukovatelnost“ níže).
Binární & build detaily
- Platforma: Windows x64, MSVC (Visual Studio).
- Export:
extern "C" __declspec(dllexport). - Zachytávání výjimek: přes C hranici žádná výjimka nejde – veřejné API vrací
bool/int. - Vlákna: tabulka instancí chráněna
std::mutex. Operace na jedné síti nejsou re-entrantní – volání na stejný handle serializujte (EA v MT5 běží obvykle jednovláknově).
Doporučená nastavení projektu (VS)
- Configuration:
Release | x64. - C++:
/std:c++17(nebo novější),/O2,/EHsc. - Runtime:
/MD(default; sdílená CRT).
(Pokud použijete/MT, jen pamatujte, že „seed sdíleného RNG přes srand“ se pak nechová stejně jako u/MD– viz níže.)
API (C rozhraní)
Všechny funkce jsou exportované s C ABI. Signatury:
// Vytvoří novou (prázdnou) síť a vrátí kladný handle, nebo 0 při chybě.
int NN_Create(void);
// Uvolní síť dle handle (idempotentní).
void NN_Free(int h);
// Přidá hustou vrstvu do sítě h.
// act: 0=SIGMOID, 1=RELU, 2=TANH, 3=LINEAR, 4=SYM_SIG
bool NN_AddDense(int h, int inSz, int outSz, int act);
// Vrací deklarovaný rozměr vstupu/výstupu sítě (0, pokud handle není validní).
int NN_InputSize(int h);
int NN_OutputSize(int h);
// Dopředný průchod: in[in_len] -> out[out_len].
// Návrat false, pokud nesouhlasí rozměry/handle/chybí vrstvy.
bool NN_Forward(int h, const double* in, int in_len,
double* out, int out_len);
// Jeden tréninkový krok (SGD) s MSE.
// Pokud mse != nullptr, vrátí aktuální MSE (po update).
bool NN_TrainOne(int h, const double* in, int in_len,
const double* tgt, int tgt_len,
double lr, double* mse);
Mapování aktivací (parametr act)
| Kód | Aktivace | Poznámka |
|---|---|---|
| 0 | SIGMOID | 1/(1+e−x)1/(1+e^{-x})1/(1+e−x) |
| 1 | RELU | max(0,x)\max(0,x)max(0,x), He init |
| 2 | TANH | tanh(x)\tanh(x)tanh(x) |
| 3 | LINEAR | Identita |
| 4 | SYM_SIG | 2⋅σ(x)−1∈(−1,1)2\cdot\sigma(x)-1 \in (-1,1)2⋅σ(x)−1∈(−1,1) |
Životní cyklus sítě (doporučený postup)
h = NN_Create().- Topologie – posloupnost
NN_AddDense(...).- První vrstva definuje vstupní rozměr modelu.
- Poslední vrstva definuje výstupní rozměr.
- Rozměry musí navazovat:
out_sz(k-1) == in_sz(k).NN_AddDensevracífalse, když nesedí.
- Volitelně si ověřte
NN_InputSize(h),NN_OutputSize(h). - Trénink – opakovaně volat
NN_TrainOne(h, in, in_len, tgt, tgt_len, lr, &mse).in_lenmusí ==NN_InputSize(h).tgt_lenmusí ==NN_OutputSize(h).lrje learning rate.
- Inference –
NN_Forward(h, in, in_len, out, out_len). NN_Free(h).
Sémantika & chování
- Validace rozměrů:
NN_Forward/NN_TrainOnevrací false, pokud:- handle neexistuje,
- síť nemá žádné vrstvy,
- délky bufferů (
in_len,out_len/tgt_len) nesouhlasí s topologií.
- Bezpečnost paměti: DLL nikdy nealokuje/vlastní Vaše buffery. Předávejte ukazatele na platné oblasti paměti o deklarované délce.
- Numerika:
- Vstup/target/výstup jsou
double. - Gradient clipping ±5 per-neuron stabilizuje učení.
- Inicializace vah: He (ReLU) / Xavier-like (ostatní).
- Vstup/target/výstup jsou
- Více instancí: libovolně mnoho simultánních sítí (jeden proces, různé handle).
- Re-entrance: volání na stejný handle neprovádějte souběžně.
Reprodukovatelnost (RNG)
- Váhy se inicializují přes
std::rand()na U[-1,1] * scale. - Deterministické běhy vyžadují seedování
std::srand(...)v kontextu stejné CRT, v níž běží DLL. Prakticky:- při build-u s
/MD(sdílená CRT) může seed v host procesu sdílet RNG se DLL – není to ale formálně garantováno; - „čisté“ řešení: přidat si do DLL export
NN_Seed(unsigned)a volat ho z MQL5 (v tomto build-u zatím není).
- při build-u s
Ukázky použití v MQL5
1) Import blok
#import "NNMQL5.dll"
int NN_Create();
void NN_Free(int h);
bool NN_AddDense(int h,int inSz,int outSz,int act);
bool NN_Forward(int h,const double &in[],int in_len,double &out[],int out_len);
bool NN_TrainOne(int h,const double &in[],int in_len,const double &tgt[],int tgt_len,double lr,double &mse);
int NN_InputSize(int h);
int NN_OutputSize(int h);
#import
Pozn.: v MQL5 se pro „pole jako pointer“ používá
const double &arr[].
2) Sestavení nejjednodušší sítě (např. 4→8→1) a inference
int h = NN_Create();
if(h<=0){ Print("Create failed"); return; }
bool ok = true;
ok &= NN_AddDense(h, 4, 8, 1); // RELU
ok &= NN_AddDense(h, 8, 1, 3); // LINEAR
if(!ok){ Print("Topology failed"); NN_Free(h); return; }
double x[4] = {1,2,3,4};
double y[1];
if(!NN_Forward(h, x, 4, y, 1)) Print("Forward failed");
Print("y=", y[0]);
NN_Free(h);
3) Online trénink (SGD) – jeden krok
double x[4] = { /* features */ };
double t[1] = { /* target */ };
double mse=0.0;
double lr = 0.01;
bool ok = NN_TrainOne(h, x, 4, t, 1, lr, mse);
if(!ok) Print("TrainOne failed");
else Print("MSE=", DoubleToString(mse,6));
4) Typický trénink v EA (pseudo)
- V
OnInit: vytvořit síť a topologii. - V
OnTimer: náhodný vzorek z datasetu →NN_TrainOne(...), logovat MSE, po dosažení cíle stopnout timer. - V
OnTick/OnCalculate: volatNN_Forward(...)pro predikce.
Doporučení pro praxi
- Normalizujte vstupy/targety (mean/std, min-max) – výrazně stabilnější učení.
- Volte LR podle aktivace: vyšší pro ReLU, nižší pro „měkké“ akt.
- Nejprve zkuste LINEAR výstup (regrese).
- U sekvenčních dat dejte pozor na leak (trénujte jen z minulosti na budoucnost).
- Chcete-li adaptivní LR (plateau/cosine/CLR), řešte v MQL –
lrje volný parametr.
Chování funkcí (tabulka rychlé reference)
| Funkce | OK stav (true/>0) | False/0 znamená |
|---|---|---|
NN_Create | Kladný handle | Alokace selhala (vzácné) |
NN_Free | — | — (idempotentní) |
NN_AddDense | Vrstva přidána | Handle neexistuje / nenavazují rozměry |
NN_InputSize | Deklarovaný vstup | 0, když handle neexistuje / síť prázdná |
NN_OutputSize | Deklarovaný výstup | 0, když handle neexistuje / síť prázdná |
NN_Forward | Výstup zapsán do out[] | Handle/rozměry špatně / síť prázdná |
NN_TrainOne | Proveden update, *mse (pokud nebyl nullptr) | Handle/rozměry špatně / síť prázdná |
Detailní poznámky k implementaci (pro audit)
- Forward: každá vrstva provede z=Wx+bz = W x + bz=Wx+b, uloží
last_in,last_z,last_out. - Backward: přepočte
dL/dz = dL/dy ⊙ f'(z)(pro ReLU používáx>0). Clipping ±5.
Update:b -= lr * dL/dz,W -= lr * (dL/dz) * last_in^T.
Gradient do předchozí vrstvy:W^T * dL/dz. - Ztráta:
MSE = mean((y - t)^2), gradientdL/dy = 2(y - t)/n. - Inicializace:
u ∈ U[-1,1],w = u * scale, kdescale = sqrt(2/in)pro ReLU, jinaksqrt(1/in).
Tipy k výkonu
- Nevytvářejte a neničte síť v každém ticku. Alokujte v
OnInit, použijte timer. - Minimalizujte kopie vstupních polí v MQL; recyklujte buffery.
- Pokud inference/trénink voláte často, zvažte větší Lookback → oceňte
in_lenvs. rozumná topologie.
Kompatibilita s MQL5
- MQL5
double↔ Cdouble(8B) je kompatibilní. - MQL5 předává pole jako „reference na pole“:
const double &in[].
DLL čte/zapisuje přes syrové pointery; Vy garantujete délku. - Bool v MQL5 ↔
boolv DLL – chová se standardně (0/1).
Troubleshooting (nejčastější chyby)
NN_AddDensevrací false: navazující rozměry nesouhlasí (např. 8→16, potom 32→1).
Opravte na 8→16→1 nebo 32→… podle záměru.NN_Forward/TrainOnevrací false: špatnéin_len/out_len/tgt_lenvůči topologii, nebo handle už neexistuje.- „Nic se neučí“: zkuste jiný
lr, přenormujte data, ověřte, že cílová funkce není mimo rozsah aktivace (třebaSIGMOIDvs. neregulovaná regrese). - Repro běhy: bez explicitního seeding exportu determinismus není zaručen.
Licenční poznámka
„MIT-like spirit“ – použijte volně, uvádějte autorství.
Mini „Quick-Start“ (kompletní MQL5 skelet)
#import "NNMQL5.dll"
int NN_Create(); void NN_Free(int h);
bool NN_AddDense(int h,int inSz,int outSz,int act);
bool NN_Forward(int h,const double &in[],int in_len,double &out[],int out_len);
bool NN_TrainOne(int h,const double &in[],int in_len,const double &tgt[],int tgt_len,double lr,double &mse);
int NN_InputSize(int h); int NN_OutputSize(int h);
#import
int h=-1;
int OnInit(){
h=NN_Create(); if(h<=0) return INIT_FAILED;
if(!NN_AddDense(h, 32, 64, 1)) return INIT_FAILED; // RELU
if(!NN_AddDense(h, 64, 1, 3)) return INIT_FAILED; // LINEAR
return INIT_SUCCEEDED;
}
void OnDeinit(const int r){ if(h>0) NN_Free(h); }
void OnTimer(){
static double x[32], t[1], y[1]; double mse;
// ...naplň x[32] a t[1]...
NN_TrainOne(h, x, 32, t, 1, 0.01, mse);
NN_Forward(h, x, 32, y, 1);
Print("y=",y[0]," mse=",mse);
}int NN_Create();
Co dělá: Vytvoří prázdnou NN instanci a vrátí její handle (>0).
Návrat: >0 = platný handle, 0 = selhání alokace (vzácné).
Pozn.: Síť je prázdná, dokud nepřidáš vrstvy přes NN_AddDense.
void NN_Free(int h);
Co dělá: Uvolní síť s handlem h.
Parametry:
h– handle dříve vrácenýNN_Create.
Vlastnosti: Idempotentní (volání na neexistující/neplatný handle nevadí). Po uvolnění jehneplatný.
bool NN_AddDense(int h, int inSz, int outSz, int act);
Co dělá: Přidá dense vrstvu do sítě h.
Parametry:
h– handle sítě.inSz– počet vstupů vrstvy.outSz– počet neuronů (výstupů) vrstvy.act– kód aktivace:0SIGMOID,1RELU,2TANH,3LINEAR,4SYM_SIG (sym. sigmoida).
Návrat:true= vrstva přidána;false= handle neexistuje nebo nenavazují rozměry (tj.outSzpředchozí vrstvy ≠inSznové).
Vedlejší efekty:
- První přidaná vrstva fixuje vstupní dimenzi sítě (
NN_InputSize). - Poslední přidaná vrstva definuje výstupní dimenzi (
NN_OutputSize). - Biasy jsou nulové; váhy se inicializují He (pro ReLU) nebo Xavier-like (ostatní).
bool NN_Forward(int h, const double &in[], int in_len, double &out[], int out_len);
Co dělá: Inference – dopředný průchod sítě h.
Parametry:
h– handle sítě.in[]– vstupní vektor (MQL5 předává jako „reference na pole“).in_len– délkain[]; musí býtNN_InputSize(h).out[]– předalokované výstupní pole, do kterého DLL zapíše výsledek.out_len– délkaout[]; musí býtNN_OutputSize(h).
Návrat:true= výstup zapsán doout[];false= špatný handle, prázdná síť, nebo délky neodpovídají topologii.
Pozn.: Nemění váhy; pracuje vdoublepřesnosti.
bool NN_TrainOne(int h, const double &in[], int in_len, const double &tgt[], int tgt_len, double lr, double &mse);
Co dělá: Jeden krok tréninku (SGD) na jednom vzorku.
Parametry:
h– handle sítě.in[]– vstupní vektor.in_len==NN_InputSize(h).tgt[]– cílový vektor.tgt_len==NN_OutputSize(h).lr– learning rate (doporučuj normalizovat data a LR řídit z EA).mse– výstupní parametr: hodnota MSE z právě spočteného forwardu. Technicky je MSE počítáno před aplikací update (forward → MSE → gradient → update).
Návrat:true= update proveden (váhy změněny),false= chyba handle/rozměrů/prázdná síť.
Pozn.: Obsahuje gradient clipping (±5 per neuron) pro stabilnější učení.
int NN_InputSize(int h);
Co dělá: Vrátí očekávanou vstupní dimenzi sítě h.
Návrat: >0 = velikost vstupu; 0 = neplatný handle nebo síť nemá vrstvy.
int NN_OutputSize(int h);
Co dělá: Vrátí očekávanou výstupní dimenzi sítě h.
Návrat: >0 = velikost výstupu; 0 = neplatný handle nebo síť nemá vrstvy.
Krátké „kontrakty“ (před/podmínky)
NN_AddDense:outSz(prev) == inSz(new); jinakfalse.NN_Forward:in_len == NN_InputSize(h)aout_len == NN_OutputSize(h).NN_TrainOne:in_len == NN_InputSize(h)atgt_len == NN_OutputSize(h).- Pole
in[]/out[]/tgt[]musí být volajícím správně alokovaná; DLL je jen čte/zapisuje.

Autor: Tomáš Bělák